

AI is Evolving Fast – The Latest LLMs, Video Models & Breakthrough Tools
Breakthroughs in multimodal search, next-gen coding assistants, and stunning text-to-video tech. Here’s what’s new:


Welcome to Visually AI!
The last couple of years have been overwhelming with the lightspeed pace of generative AI developments, but the past two weeks made me feel like I was drowning and struggling to keep up!
I have been traveling and working full-time on an incredible project (I hope to tell you more soon!), so I will try to share the news I’ve been able to keep up with :)
LLM News

Grok 3 Officially Launched
Grok 3 officially launched on February 17, 2025, after delays from its anticipated 2024 debut.
You don’t have to use it on 𝕏 - there is an iOS app here and Android coming soon.
New Features
DeepSearch: Real-time web & 𝕏 (Twitter) search for clearer, up-to-date answers.
Think Mode: Step-by-step problem-solving for complex queries.
Multimodal Abilities: Can analyze images; image generation (Aurora) is coming soon.
I have used Grok 3’s DeepSearch feature for various questions, including 3D mesh tool functionality and generative AI object removal in videos. I found it thorough, and I appreciate the ability to see the model’s thought process.
Here’s an example with my question:
“What is the average length of time for films to be released on streaming platforms after they premiere in theaters?”
Claude 3.7 Sonnet & Claude Code
Claude 3.7 Sonnet, Anthropic’s latest AI, just dropped this week and it’s a big deal with its new “extended thinking” mode that tackles tough tasks like coding and math step-by-step. People have been using it for things such as pairing it and the new experimental Claude Code with AI coding tools like Cursor or Bolt for coding, debugging, and full-stack app development.
Claude 3.7 Sonnet is available now on Claude.ai.
Sign up for Claude Code waitlist here.

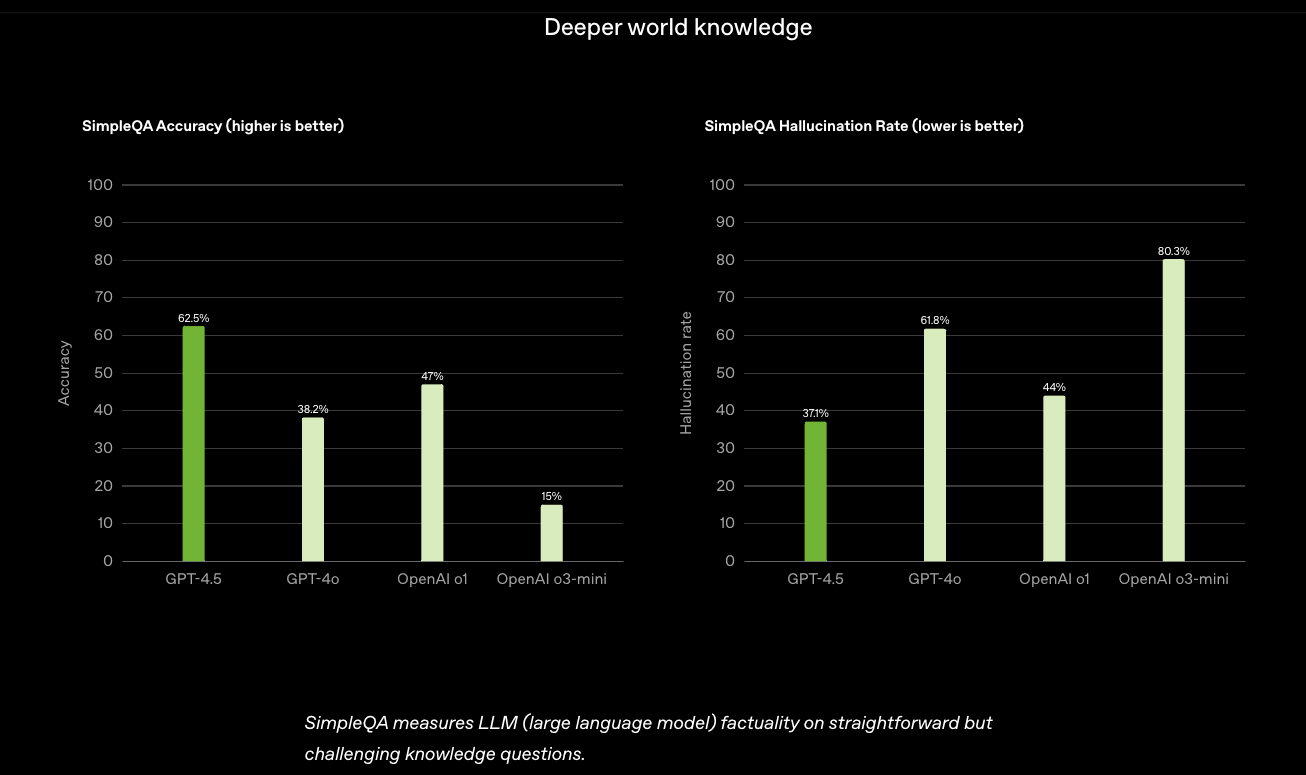
OpenAI GPT-4.5
OpenAI’s GPT-4.5 hit the scene a few days ago, as a research preview, bringing a beefier knowledge base and smoother chats for tasks like writing and coding.
It will be available first to ChatGPT Pro users, with a rollout to others soon after. It features real-time search and file uploads, but don’t expect voice or video support just yet.
Alibaba Wan-2.1 video goes open source

The latest Chinese video model is incredible with complex motion and prompt adherence with amazing video quality with text to video and image to video capabilities.
It’s now open source and available on the native support in ComfyUI, Hugging Face, Replicate, Fal, and more.
You can also try the model quickly on the Alibaba Cloud Tongyi platform (with a Chinese phone number), Freepik, Nim, Krea, Imagine, and developer platforms such as Replicate, Fal, and Hugging Face.
I’ll write more about Wan 2.1 soon, but here’s a great example of the text to video results - upscaled from 480p and sound added on Nim:
📽️ Video Model Comparison

I do these comparisons frequently to measure the improvements in different models for text or image to video prompts. I hope it is helpful for you, as well!
I included 6 models for an image to video comparison:
Pika 2.1 (I will do one with Pika’s new 2.2 model soon)
Adobe Firefly Video
Runway Gen-3
Kling 1.6
Luma Ray2
Hailuo I2V-01
This time I used an image generated with Magnific's new Fluid model ( Google DeepMind's Imagen + Mystic 2.5 ), and the same prompt in each model x 2 generations and chose my favorites below:
"Low-angle dolly shot along the temple's edge, capturing the contrast between classical architecture and wild nature. Orange-tinted waves crash against rocks below as crimson clouds streak across the sky. Shot on anamorphic lenses, ultra-detailed textures, dramatic atmospheric lighting."
📸 AI Snapshots
Google announced Gemini Coding Assist is available for developers worldwide for free, with a personal Gmail account. It includes the highest available usage limits and code review assistance - install in VS Code, GitHub, or JetBrains IDEs.
Pika introduced Pikaswaps, which lets you easily change areas of videos with a text prompt and painting or describing the area you want to change. You can also upload an image for a specific object reference. I’ve had great results with describing the area and replacement with text. Here’s an example where I described a “yellow background” to change to "A [a beach at sunset] visible in the background":
Now you can use an image reference in Runway Frames. This feature is useful because it generates a detailed prompt from your image and you can capture different styles using Frames style presets and adjusting the Aesthetic Range for more variety in results. Here is a quick example using my Midjourney image in Frames:
I was honored to be included in a recent showcase from Kling AI with several other Creator Partners:
I2V-01 Director Mode available to everyone now on Hailuo AI. It gives you precise camera control with a range of motion presets or your own prompt descriptions with image to video generations. Here is my example with a Midjourney image and prompt: "[Push in] on the fierce samurai [Shake]"
🌎 AI Developments All Over The Globe
Google Veo 2 Integration in YouTube Shorts: Google rolled out DeepMind’s Veo 2, a state-of-the-art video generation model, to YouTube Shorts creators in select countries (U.S., Canada, Australia, New Zealand). It generates 1080p cinematic clips from text prompts, with enhanced realism and SynthID watermarking, outpacing competitors like Sora in some human evaluations.
ByteDance’s OmniHuman-1 and Phantom Unveiled: ByteDance introduced OmniHuman-1, an AI model that creates lifelike videos from a single photo, trained on 18,700+ hours of video data, excelling in motion and audio sync. Alongside it, their "Phantom" system ensures subject consistency across video clips, sparking both excitement and deepfake concerns.
UK AI Regulation on Child Abuse Imagery: The UK Home Office introduced laws banning possession or distribution of AI tools generating child sexual abuse imagery, a global first. Triggered by a quadrupling of cases in 2024, it underscores the urgency of tackling generative AI’s dark side.
🚀 My Recent Top AI Tools Picks
a0.dev: Quickly create mobile apps with React in minutes by chatting with the AI builder.
Demo: Zero-Shot Depth Estimation with DPT + 3D Point Cloud: This Hugging Face demo is a variation from the original DPT Demo. It uses the DPT model to predict the depth of an image and then uses 3D Point Cloud to create a 3D object.
Imagine: AI platform has Kling, Hailuo, Runway, Alibaba’s Tongyi, and Hunyuan Video - plus model training and more.
Nim: Full AI image and video platform with tools I’ve been using more and more, like MMAudio sound, video upscale, lip sync, video inpainting, and others.
Midjourney Style Reference Codes w/ Examples
Included:
• 33 --sref Codes
• 396 Downloadable Images
• 132 Prompts
🖼️ Image Prompts
Prompt: White ceramic coffee cup on rustic wooden table, steam rising, scattered coffee beans, morning light casting long shadows. Professional product photography, epic cinematic lighting

Prompt: Dawn breaks over a misty Pacific Northwest forest. Wide establishing shot from elevated position, ancient Douglas firs pierce through rolling fog banks. Golden sunbeams filter through branches. Cinematic depth, moody atmosphere, shot on ARRI digital.

Prompt: isometric view of van Gogh starry night painting

🎥 Video Prompts
Image to Video Prompt: Intimate portrait sequence in a gothic cathedral at magic hour. Camera gracefully orbits a young woman with intricate braids and leather jacket, moving through pools of golden light cast by ancient chandeliers. Dramatic depth of field highlights architectural details in the soaring vaulted background. Cinematic lighting, precise focus pull, ultra-smooth motion.
Kling AI 1.6
Image to Video Prompt: Slow dolly shot. Camera gracefully moves from behind a hooded figure meditating on the edge of a cyberpunk cityscape. Brilliant fuchsia and cerulean sunset bathes everything in otherworldly light. Holographic symbols spiral outward as the figure gestures, while massive crystalline towers gleam in the distance. Hyper-detailed photorealism, dreamlike atmosphere.
Luma Ray2 Img2Video
Text to Video Prompt: [Tracking shot, Pedestal down] Following a falcon as it dives through a narrow canyon, wings nearly touching the red rock walls [Pull out]. Dynamic motion, epic scale.
Hailuo AI I2V-01 Director Mode
Thank you for reading.
Have a creative week!

Wow, so much is happening in AI! The updates on LLMs like Grok 3 and GPT-4.5 are impressive. And that Alibaba video model is amazing. Makes you wonder what's next. I'm especially curious about tools like https://qwenimageedit.art/ and how they'll change image editing!
Genuinely stunning lifelike examples in the post. What is your take on more informative formats? Such as this example video of your post: https://app.symvol.io/videos/ai-is-evolving-fast-the-latest-llms-video-models-and-breakthrough-tools-1184